继续上文,在学习完GCN后,争对其两个问题,又分别提出了两种网络:GAT、Graph Sage,但看了许多知识图谱增强的NLP文献,里面GCN和GAT占了大多数,所以本文重点对GAT进行介绍。
GAT
GCN在融合邻居信息时边权是固定的,灵活性较差,GAT针对这个问题在图中加入了注意力机制,由模型学习更新每个边的权重
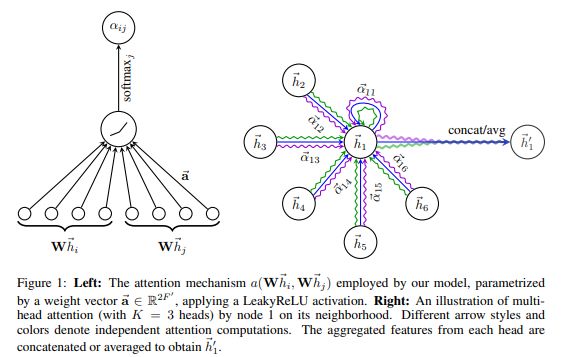
结合以下公式,理解attention的计算过程:
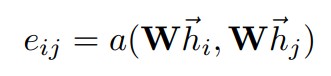
以目标节点
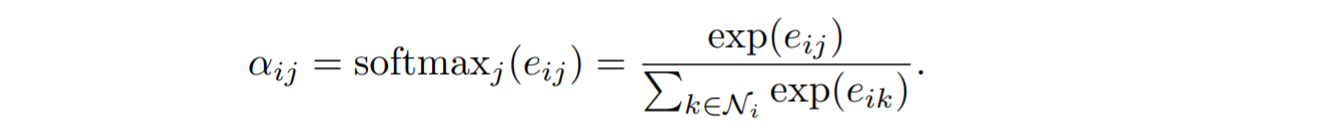
对每个邻居节点进行以上操作(为了加速计算,实际实现利用矩阵运算一步解决)可以得到目标节点和各邻居的注意力向量
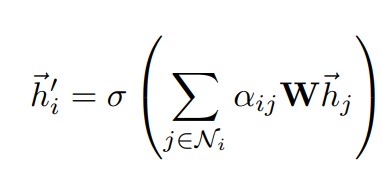
此外,为了增强特征提取的效果,原论文中还采用多头注意力机制,即让k个头分别做注意力计算,最后将每个头的结果concate起来,在网络的最后一层输出维度一般较小,则将concate改为做平均。
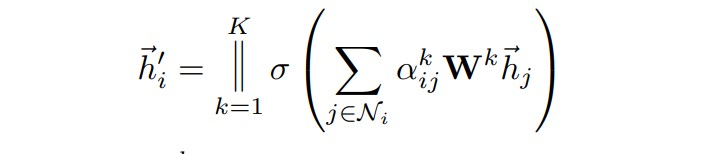
GAT的变体——Gated Attention Network(GaAN)
键值注意力机制
与GAT所使用的注意力机制,GaAN使用的是键值注意力和点积注意力机制,计算方式与Transformer中使用的多头CrossAttention相同,用公式表示为
其中Q为查询向量,在GCN中即为当前的目标节点特征
门控注意力
在多头注意力中,为了体现不同的头捕捉的特征的区别,为每个头加入门控机制以决定该头捕获的特征的重要程度。每个头的门控值由目标节点和邻居节点通过卷积网络
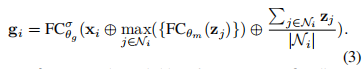
其中
至此对于GCN和GAT以及其几个变体的介绍都结束了,总的来讲,抛开中间复杂的数学公式(e.g.,拉普拉斯矩阵、傅里叶变换,想深入的可以去学一学。),GCN的思想还是很容易理解的,其中图Attention的机制也和CNN、RNN的机制类似,接下来就是利用pytorch+DGL搭建一个GAT网络了。